开源项目|今天不当拼图仔,机器视觉来拼图
这两天有个脑洞想要实现一下,现在有了一点眉目在这边报个喜。
传统项目开发过程中UI出图之后,进行切图。然后由UE或者程序去进行游戏引擎内的拼接,这个过程虽然伤害不大但是费眼神。那么有办法解决吗?
有,还不少,PSD to Unity 的类似方案。实际上这部分拼图的工作让UI承担了。笑容只是从UI的脸上转移到了别人脸上。工作量仍然存在。
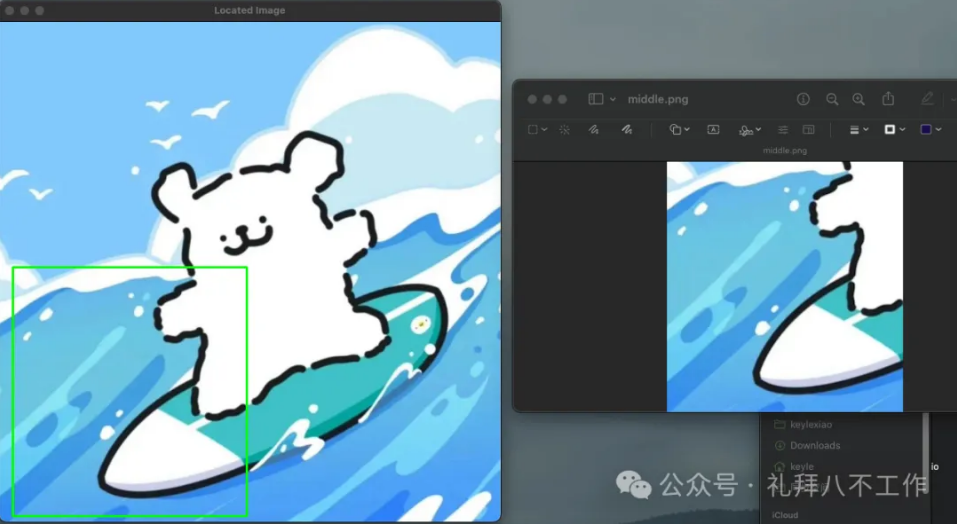
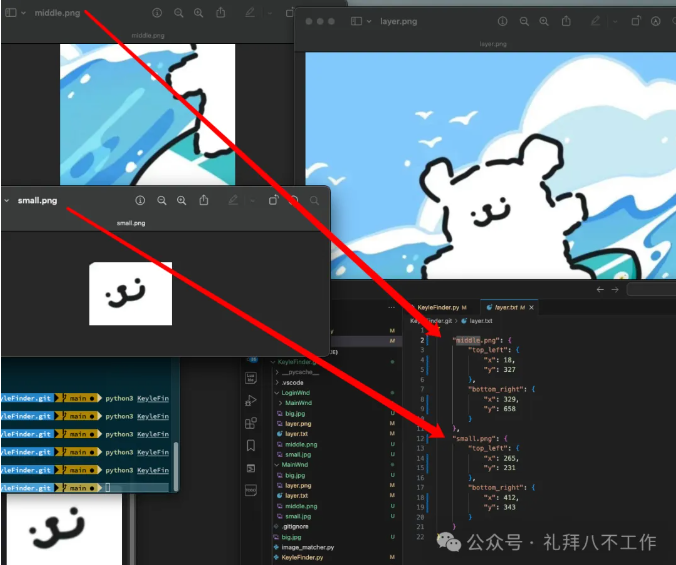
既然如此,我们不妨换个思路,旧的流程不变,仍旧是UI出layer(底板图)以及切片过的UI。我们通过机器视觉将切片定位到layer图的精确坐标。
算法如下:
1 | def match(self, single_image_path, mode=cv2.TM_CCOEFF_NORMED, show_preview=False): |
最后将这个坐标保存,以及定义一些切片图的命名后缀。
接下来要做的工作就是拿到坐标信息,在不同的UI环境下自动生成摆放好的UI界面。
现在我已经做了如下工作:
路径扫描,图片识别,按照文件大小排序记录位置信息保存在当前文件夹下,如果有深一层路径继续往下扫描。
目前看下来准确率非常高,后面有空就在fairygui,或者ugui中实现一版,自动拼图工具。
项目地址:
本文标题:开源项目|今天不当拼图仔,机器视觉来拼图
文章作者:Keyle
发布时间:2024-04-18
最后更新:2024-08-20
原始链接:https://vrast.cn/posts/32254/
版权声明:©Keyle's Blog. 本站采用署名-非商业性使用-相同方式共享 4.0 国际进行许可