LipSync插件调研1
这周会计划研究LipSync方向,会写一些资料记录过程。本篇并不讲详细使用步骤,只讨论其功能实现。
本篇评测的插件列表如下:
** SALSA With RandomEyes **
** UniLip **
评测的方向: 1. 嘴型同步
评测角度: 1. 实现方式 2. 可用性
SALSA With RandomEyes
插件包含 SALSA与RandomEyes 两部分。这里与后文并不关注RandomEyes相关话题。
实现方式
美术:使用 blend shape 制作 三口型
在分析了插件包内的 boxHead.fbx 文件之后看到了如下层级结构:
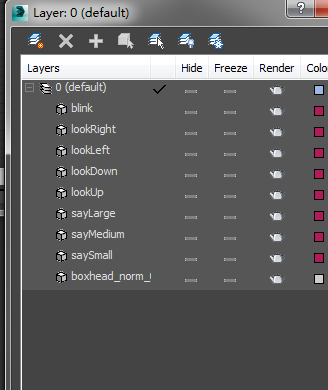
具体做法在层级面板上已经可以反推出来美术的制作流程
- 美术这边首先在不同的层级上作出不同的口型表现,本插件要求美术在上图中三个Say开头的层级上实现三个口型
- 使用 blend shape 绑定。这是一种做融合动画(面部口型)的特殊做法。为什么不用骨骼动画?因为用骨骼动画做节点太多了。
策划配置:三变量
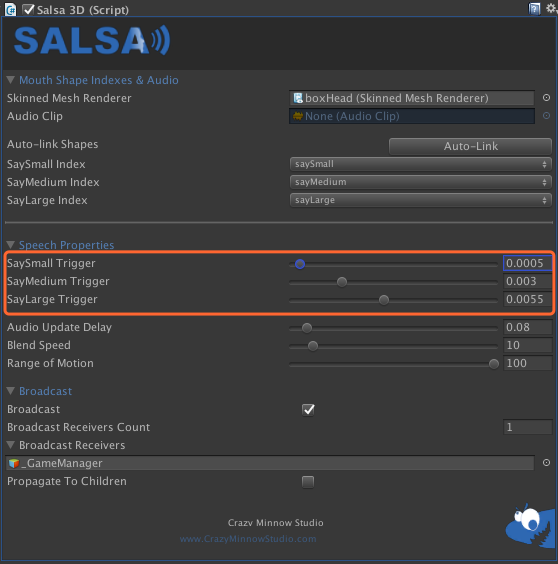
程序实现:控制面部口型过渡
为了达到控制口型的目的,SALSA启动了一个携程在每个audioUpdateDelay周期内对音频采样。后获得 average
1 | private IEnumerator UpdateSample() |
通过 average 配合策划设置的三个数指(saySmallTrigger/sayMediumTrigger/sayLargeTrigger) 来控制什么时间点融合什么动画。
1 | private void Update() |
UniLip
此插件可实现与 SALSA With RandomEyes 的实现原理一样,侧重点不同,他开放了更多的口型给策划配置。
此函数等于 SALSA With RandomEyes 在上文例举的 UpdateSample 代码片段。不同的是作者将这段代码放在了Update循环之中,从纯代码上看效率比SALSA With RandomEyes还要差。
1 | void AudioProcess() |
与 SALSA With RandomEyes 不同的地方是他支持了多个口型的随机。
{kind=link}
可用性
可借鉴优点
- 策划门槛低,使用美术制作的 blend shape 减小导出模型体积,并且灵活程序控制,程序只需要通过一些策划配置好的条件便可以将任意两个口型进行过渡。
- 这种做法不存在动画衔接问题。因为所有的状态我们都可以看作是两个clip之间的过渡。
- 通过采样率与音频的高低来控制脸型与嘴形的同步,在某种意义上来说是一种假同步,正是这种”假同步”才不存在多语言问题。
- 免预处理,导入即用
缺点
- 表现上不足,假同步解决了多语言问题但是带来了表现力不足,仔细看口型与音频完全不是一回事,但通常我们不会仔细看。
- 移动端效率堪忧,在移动端上大规模使用本做法
周期采样音频是有效率问题的。 - 不能直接使用,如果使用此中做法开发口型系统这两个插件都不能直接用,需要基于项目对插件进行二次开发。
🔗 捕捉音谱
🔗 用Unity3D内部频谱分析方法做音乐视觉特效的原理说明
🔗 How to animate a character with blend shapes
本文标题:LipSync插件调研1
文章作者:Keyle
发布时间:2018-04-23
最后更新:2024-08-20
原始链接:https://vrast.cn/posts/a08d0c34/
版权声明:©Keyle's Blog. 本站采用署名-非商业性使用-相同方式共享 4.0 国际进行许可