LipSync插件调研2
这周会计划研究LipSync方向,会写一些资料记录过程。本篇并不讲详细使用步骤,只讨论其功能实现。
本篇评测的工具实现方式都相近,插件列表如下:
LipSync Pro【U3D】
EasyTalk【U3D】Lipsync Tool【美术用】Face and lips
评测的方向: 1. 嘴型同步 2.面部表情
评测角度: 1. 实现方式 2. 可用性
一般有语音层的 LipSync 工具结构都相似

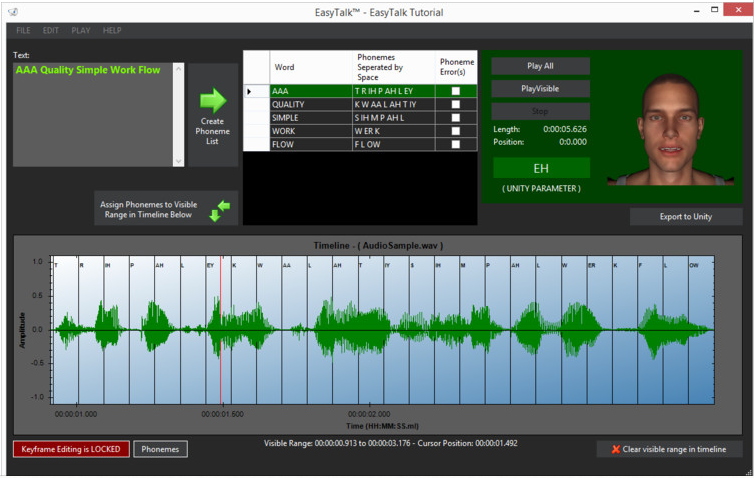
语音识别层介绍
在LipSyncPro中的CMUSphinx语音识别层
在介绍实现方式之前我们先深入一下语音识别层,原因是此类型插件都使用了语音识别出的数据作为驱动口型的数据源。
CMUSphinx 是一个开源组件 作为语音识别层层的核心 ,下文是简介
[CMU Sphinx, also called Sphinx in short, is the general term to describe a group of speech recognition systems developed at Carnegie Mellon University. These include a series of speech recognizers (Sphinx 2 - 4) and an acoustic model trainer (SphinxTrain).
In 2000, the Sphinx group at Carnegie Mellon committed to open source several speech recognizer components, including Sphinx 2 and later Sphinx 3 (in 2001). The speech decoders come with acoustic models and sample applications. The available resources include in addition software for acoustic model training, Language model compilation and a public domain pronunciation dictionary, cmudict.
Sphinx encompasses a number of software systems, described below. —来自维基百科](https://en.wikipedia.org/wiki/CMU_Sphinx)
在CMUSphinx之上使用语音训练创建语言模型
CMUSphinx 使用的语言库是可以自己训练的 Building a language model。工程量比较大,如果没有做好充足准备(资源)不建议自己训练语言库。我们自己训练的库是需要优化的,不是做完就能用,良好的语音模型拥有更高的识别率,在高识别率的前提下我们最终得到的口型会更加准确。下面例举了一些做语言训练需要的资源
1.真人进行训练
训练之前,假设你有充足的数据:
用于单个人的指令应用,至少需要一小时录音,
用于很多人指令应用,需要200个录音人,每人5小时
用于单个人的听写,需要10小时他的录音
用于多个人的听写,需要200个说话人,每人50小时的录音
同时你要有这门语言的语音学知识,以及你有足够的比如一个月的时间,来训练模型
2.使用机器学习
1.您必须为指定的语言收集音频材料。实际上这不是这么复杂的事情。有声书本、电影和播客提供足够的录音构建良好的声学模型。
2.语音学习需要您构建一个框架,用于跟踪错误的发音。包括代不正确的发音和得分。这里可以使用 cmusphinx 的机器学习。
可用性
可借鉴优点
- 速度快,基于语音识别可以快速匹配出所有的音素,并且映射相应的口型
- 表情多,可以定制非常多的口型与面部表情
- 可修改,可以自己手动编辑已经识别完毕的【音频对应的口型配置文件】
缺点
- 每种语言需要对应的声学与语言模型
- 难深度定制,我们只能定制表层使用,深入到语音识别层面很难。
补充资料 Lipsync Tool
对 Lipsync Tool 这款工具进行一些补充说明。下文是一些技术标准
目前支持导出格式如下,主要在影视方向,这里提到有简单的脚本导出但是不确定实现,他并未支持任何的游戏引擎。目前只是衔接了影视与建模软件。
It exports a simple text format readable from most scripting languages.
3ds max script for creating animations in max from lipsync tool files
MAYA .mov files, melscript (Lipscript) importer
.swf, .as : Macromedia Flash Files
🔗 CMUSphinx介绍
🔗 SOX音频处理库
🔗 Building a language model
🔗【sphinx】中文声学模型训练
🔗 语音识别的基础知识与CMUsphinx介绍
🔗 Lipsync Tool官网 annosoft价格表
本文标题:LipSync插件调研2
文章作者:Keyle
发布时间:2018-04-24
最后更新:2018-05-11
原始链接:https://vrast.cn/posts/3bc1c7b4/
版权声明:©Keyle's Blog. 本站采用署名-非商业性使用-相同方式共享 4.0 国际进行许可